Volkswagen, a global giant in the automotive industry, has come to Stermedia for the fourth time to optimize production processes using artificial intelligence mechanisms.
What the customer was looking for was the ability to determine the suitability of individual measuring devices, as well as a system informing about potential errors in the early production process.
HOW DOES THE WHOLE PROCESS LOOK LIKE?
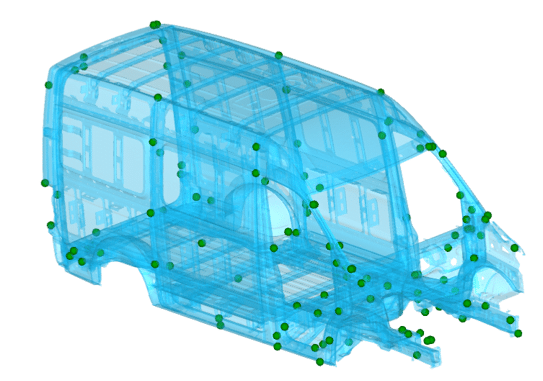
All components of the car are inspected many times at various stages of production. Each of the many production lines, through which a component passes, has its own specificity. Take, for example, a welding shop where the geometry of the car is shaped. Here, the compliance of the obtained product is checked against its model version. This control process includes verification of the location of previously established sensitive points such as bolt fastening or sheet metal bending.
MEETING THE STANDARDS – TEST TIME
After passing the entire process, the finished car is subjected to thorough tests, during which a group of experienced specialists determines whether the car meets stringent quality standards. If any irregularities are found, the defective component must be repaired. The company needs to create more dynamic component quality testing cycles. Returning to a said welding shop, if the prepared hole in which the lamp is to be mounted is too small, this problem will only be detected at the assembly plant. In the measurement data, however, information about this hole is still collected at the welding shop and it is at the welding shop that this will eventually be repaired.
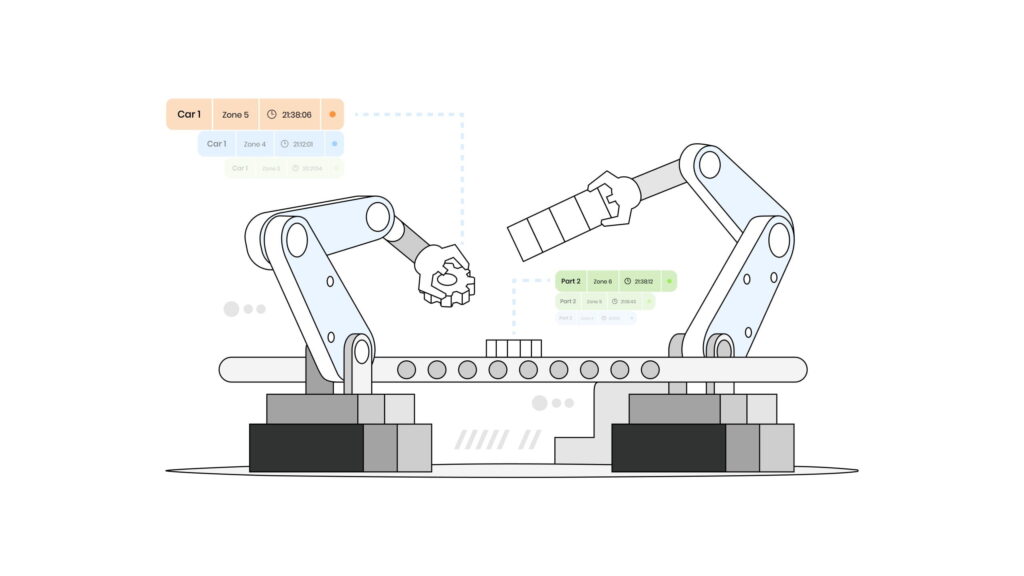
The complete solution consists of 2 stages:
- Measurement point analysis. The answer to the question of which measuring points have the greatest utility – this effectively indicates the potential occurrence of error.
- Automatic system that creates decision models. Based on effective measuring points, you can create a predictive model that will inform you in advance about potential errors, allowing you to take quick action. This in turn translates into savings on materials and less workload.
REQUEST
The Stermedia AI team received historical data from the production line containing measurement data for cars and errors observed for them. Maciej Pawlikowski, Data Scientist at Stermedia said:

Measurement information came from over 160,000 measurement points. In addition, the analyzes showed high data quality variability. Particularly problematic here were the frequent shortcomings of some measurements for some cars.
Maciej Pawlikowski, Data Scientist, Stermedia
To get the best performance, the project was defined as making a tool that could create new AI models on request and support any type of error based on the input data. This data consists of car indexes with information about the occurrence of a modeled error. This tool is to independently select the points to create a model and create the optimal model.
The tool is based on two pillars:
- Automatic feature selection
- Machine learning (and testing its effectiveness)
AUTOMATIC FUTURE SELECTION
- How to choose features?
Features are selected based on statistical analysis. The data scientists team at Stermedia chose a recursive selection approach. It is done by starting from all possible measurement points, then successively rejecting those whose significance for the modeled problem is negligible. As a result, only the essential ones remain (this is the so-called elimination method).
For example, by modeling the correct position of the glass, the method of elimination can exclude, for example, points determining the corrugation of the trunk plate. It does not affect the glass in any way. However, it can be seen that the nature of the setting of the mainframe at the rear of the car, however distant, can be useful in modeling. An example is the incorrect transmission of stress.
MACHINE LEARNING
- How to choose a model?
Let us remind you that measuring points relevant to the modeled problem have already been established. At this stage, you should use these points to decide if an error occurs or not.
In the earlier, broad analysis of this subject, a number of configurations of artificial intelligence models which performed well in the field of modeled issues were selected. Then, each of these prepared architectures was patched upon the received data, and based on the obtained results, it was decided which model works best.
It is worth noting that the application interface allows the user to use the user-defined list of used measuring points, e.g. to confirm certain expert hypotheses.
MODELS USED FOR CLASSIFICATION
xgboost, svm, logistic regression, + Random Forest, + Gaussian Process Classifier
RESULTS
As a result, the client received a tool with which they can perform the analysis of measuring points, learn their predictive value, and also -based on selected points – create predictive models that provide information about possible problems that can be remedied in a timely manner.
Are you inspired?
Let’s talk about your idea.
Let’s talk



